浏览器工作原理
一、域名解析
域名解析的过程就是查找域名对应 IP 地址的过程。
- 浏览器先检查域名是否在缓存中,有返回,没有继续查找
- 在本地 hosts 文件中寻找,有返回,没有继续查找
- 主机向本地域名服务器查询,有返回,没有继续查找
- 本地域名服务器向根域名服务器查询,这个过程不会返回域名和IP的映射关系,只会告诉本地域名服务器向下级域名服务器查询
- 本地域名服务器向顶级域名服务器查询,同样告诉本地域名服务器向下级域名服务器查询
- 本地域名服务器向二级域名服务器查询,如果还有下级域名服务器,则一直进行迭代查询,直到最后一个子域,有则返回映射关系,并且本地域名服务器将结果加到自己的映射表中。没有则网页报错
二、通讯
一旦获取到服务器的 IP 地址,浏览器就会通过 TCP 三次握手与服务器建立连接。
浏览器向服务器发送 HTTP 请求报文。
服务器接受请求并处理完后返回一个 HTTP 响应报文。
浏览器接收 HTTP 响应后,浏览器通过四次挥手和服务器断开连接。
三、解析 HTML
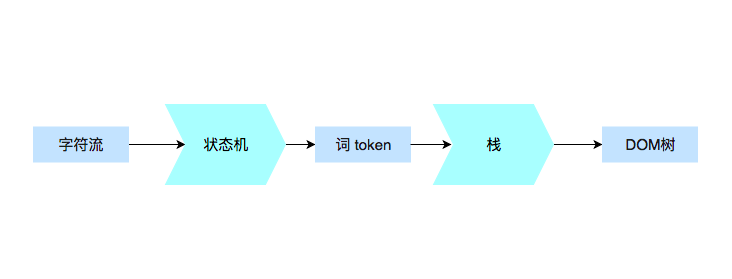
1、词法分析
词法分析是将字符流解析成词(token)的过程。HTML 无法用常规的解析器进行解析,所以浏览器用自定义的解析器来解析 HTML,解析最常见的方案是使用状态机。
词法分析器(标记生成器):负责将输入内容分解成一个个有效标记。
1 | <p class="a">text text text</p> |

关于状态机,初始状态是 数据状态。
如果遇到一个非 < 字符,那么可以认为进入了一个文本节点;
如果遇到字符
<时,进入了一个 标签状态。- 如果下一个字符是“ ! ” ,那么很可能是进入了注释节点或者CDATA节点。
- 如果下一个字符是字母,那么可以确定进入了一个开始标签。这个状态会一直保持到接收
>字符。在此期间接收的每个字符都会附加到新的标记名称上。 - 如果下一个字符是 “/ ”,那么可以确定进入了一个结束标签。直到接收
>。然后将发送新的标记,并回到 数据状态。
用状态机做词法分析,其实正是把每个词的“特征字符”逐个拆开成独立状态,然后再把所有词的特征字符链合并起来,形成一个联通图结构。
2、语法分析(构建 DOM 树)
解析器:负责根据语言的语法规则分析文档的结构,从而构建解析树。
语法分析的过程就是构建 DOM 树的过程。
浏览器先创建解析器解析词法分析得到的词(token)的同时,会创建 Document 对象。以 Document 为根节点创建 DOM 树,并不断进行修改,向其中添加各种元素。因为在规范中定义了每个标记所对应的 DOM 元素,所以解析器对 token 进行处理生成对应的元素。这些元素不仅会添加到 DOM 树中,还会添加到开放元素的堆栈中。此堆栈用于构建 DOM 树,同时纠正嵌套错误和处理未关闭的标记。
1 | - 栈顶元素就是当前节点; |
3、浏览器的容错机制
在浏览 HTML 网页时从来不会看到“语法无效”的错误。这是因为浏览器会纠正任何无效内容,然后继续工作。
4、解析 script 标签
当 HTML 解析到 script 标签时,会暂停构建 DOM 树,执行完成后才会从暂停的地方开始重新构建。也就是说,如果你想首屏渲染的越快,就越不应该在首屏执行大量 JS 文件。并且 CSS 也会影响 JS 的执行,只有当解析完样式表才会执行 JS,所以也可以认为这种情况下,CSS 也会暂停构建 DOM。
四、解析 CSS
在构建 DOM 树的过程中,如果遇到 CSS,就会解析 CSS。CSS 的解析需要经过词法分析和语法分析变成计算机能够理解的结构。
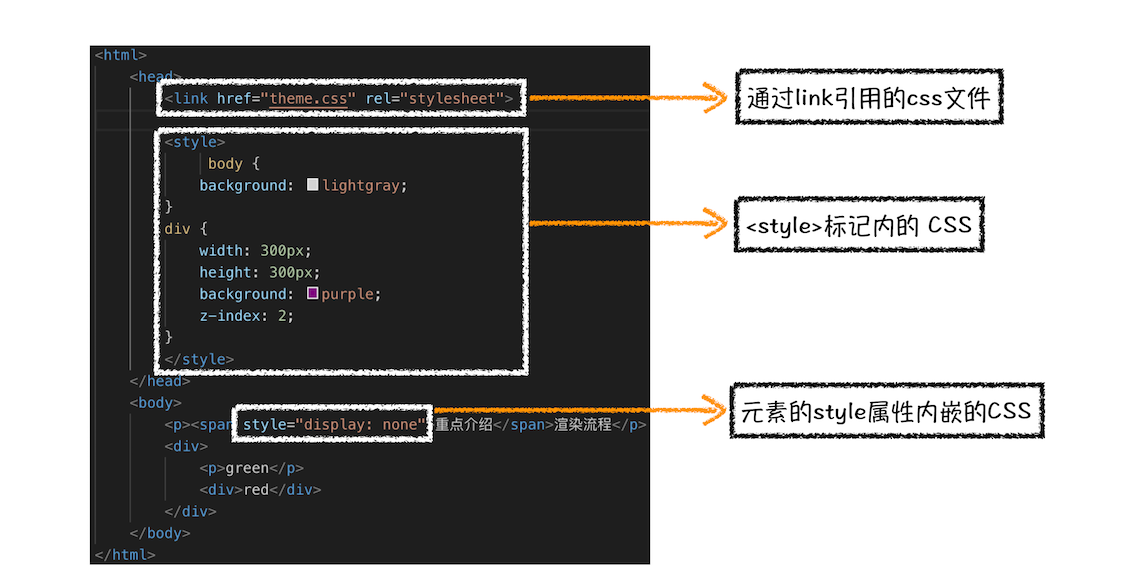
CSS 样式来源主要有三种:
通过 link 引用的外部 CSS 文件
style 标记内的 CSS
元素的 style 属性内嵌的 CSS
1、词法分析
WebKit 词法分析使用 Flex 将字符流解析成词(token)。
2、语法分析(构建CSSOM树)
WebKit 语法分析使用 Bison 解析器生成器,通过 CSS 语法文件自动创建解析器。解析器根据词(token)解析成 StyleSheet 对象,且每个对象都包含一个样式表里的多个 CSS 规则,一个 CSS 规则对象包含一个选择器和一个属性集。
根据 document.styleSheets 拿到如下的 CSS 规则。

3、生成哈希表 map
把生成的 CSS 规则集根据最右边的 selector 类型(id、class、标签、伪类选择器)放到四个类型的哈希 map 中,这样做的目的是为了在比较的时候能够很快地取出匹配第一个 selector 的所有规则。然后每条规则再检查它的下一个 selector 是否匹配当前元素。
1 | // 哈希 map 类型 |
哈希表 map 包括了所有 CSS 选择器和每个选择器的相关属性的映射。
五、构建渲染树
1、渲染树的概念
在 DOM 树构建的同时,浏览器还会根据 DOM 树和 CSSOM 树一起构建渲染树。这是由可视化元素按照其显示顺序组成的树,也是文档的可视化表示。
Firefox 将渲染树中的元素称为“框架”,WebKit 使用的术语是渲染器或渲染对象。每一个渲染器都代表了一个矩形的区域,通常对应于相关节点的 CSS 框,框的类型会受到与节点相关的“display”样式属性的影响。特别的是如果一个元素需要创建特殊的渲染器,就会替换 createRenderer 方法。
1 | RenderObject* RenderObject::createObject(Node* node, RenderStyle* style) |
2、构建渲染树的过程
从 DOM 树的根节点 document 开始深度优先遍历每个节点,根据节点的选择器去四个哈希 map 中计算该节点的样式,计算结果与该节点合并来构建渲染树。
2.1、计算样式的过程
1)选择器命中判断
为了确定哪些规则适用于节点,要进行选择器匹配,对每个节点,代码里面会依次按照 id、class、伪元素、标签的顺序取出所有的selector 进行比较判断,最后是通配符,取出所有的选择器对每个节点进行比较,如果匹配,再判断当前选择器是不是最左边的选择器,如果是则返回匹配结果;否则再递归左边的选择器是否匹配。直到左边不匹配或没有时停止。
2)设置 style
找到节点对应的 CSS 规则后,就开始计算该节点具体的 CSS 属性的值。
如果属性默认为继承值,那么 CSS 引擎会沿着 DOM 树往上查找,看看其祖先元素是否设置了该值,没有则使用默认值。CSS 引擎会把通常在一起使用的样式值存储于一个单独的对象中,该对象称为样式结构。对于每个类别的样式,存储的都是一个指向样式结构的指针。这种方式称为样式结构共享。
因为可能会有多个选择器的样式命中相同节点,且浏览器本身也提供了一些默认的样式规则(用户代理样式表)。所以需要按照它们的优先级把样式属性综合在一起。
3)调整 style
根据 CSS 属性值调整其他的 CSS 属性值。比如:把 absolute 定位、fixed 定位、float 的元素设置成 block。
2.2、渲染对象和 DOM 元素的关系
渲染对象和 DOM 元素相对应,但并非一一对应。非可视化的 DOM 元素不会插入渲染树中,例如“head”元素;如果元素的 display 属性值为“none”,那么也不会显示在渲染树中(但是 visibility 属性值为“hidden”的元素仍会显示)。
有一些 DOM 元素对应多个渲染对象。它们往往是具有复杂结构的元素,无法用单一的矩形来描述。
1 | “select”元素有 3 个渲染对象:一个用于显示区域,一个用于下拉列表框,还有一个用于按钮。如果由于宽度不够,文本无法在一行中显示而分为多行,那么新的行也会作为新的渲染器而添加。 |
- 有一些渲染对象对应于 DOM 节点,但在树中所在的位置与 DOM 节点不同。浮动定位和绝对定位的元素就是这样,它们处于正常的流程之外,放置在树中的其他地方,并映射到真正的框架,而放在原位的是占位框架。
六、布局
渲染树创建完需要給每个节点添加位置和大小信息。计算这些值的过程称为布局或重排。布局是一个递归的过程。它从根呈现器(对应于 HTML 文档的 元素)开始,然后递归遍历部分或所有的框架层次结构,为每一个需要计算的呈现器计算几何信息。
HTML 采用基于流的布局模型,大多数情况下只要一次遍历就能计算出几何信息。处于流中靠后位置元素通常不会影响靠前位置元素的几何特征,因此布局可以按从左至右、从上至下的顺序遍历文档。但是也有例外情况,比如 HTML 表格的计算就需要不止一次的遍历 。
坐标系是相对于根框架而建立的,使用的是上坐标和左坐标。根呈现器的位置左边是 0,0,其尺寸为视口(也就是浏览器窗口的可见区域)。
七、绘制
在绘制阶段,系统会遍历渲染树,将渲染树的内容显示在屏幕上。绘制工作是使用用户界面基础组件完成的。
八、总结
1)在浏览器地址栏输入URL
2)发送请求前,首先要知道 URL 对应服务器的 IP 地址,所以先进行域名解析。首先先在浏览器缓存里进行查找,然后是本地 hosts 文 件。主机向本地 DNS 服务器查询,如果没有,本地域名服务器向其他根域名服务器继续发出查询请求报文,根域名服务器告诉本地域名服务器下一步向下一个域名服务器进行查询。直到最后其他域名服务器将查询结果告诉主机。
3)客户端通过三次握手和服务器建立 TCP 链接,
4)客户端向服务器发送 HTTP 请求报文。这个 http 请求封装在一个 tcp 包中,这个 tcp 包会依次经过传输层,网络层, 数据链路层,物理层到达服务器。
5)服务器接受请求并处理完后返回一个 HTTP 响应报文。返回相应的 html 给浏览器。
6)浏览器接收HTTP响应后,客户端通过四次挥手和服务器断开连接。
7)把请求回来的 HTML 代码经过解析,构建成 DOM 树;
8)在 DOM 树的构建过程中如果遇到 JS 脚本和外部 JS 连接,则会停止构建 DOM 树来执行和下载相应的代码,这会造成阻塞,这就是为什么推荐 JS 代码应该放在 html 代码的后面
9)根据外部样式,内部样式,内联样式构建 CSSOM 树;
10)最后根据 CSSOM 树计算 CSS 属性并和 DOM 树构建渲染树;这里主要做的是排除非视觉节点,比如 script,meta 标签,排除 display 为 none 的节点。
11)根据渲染树计算每个节点的几何信息。
12)最后将各个节点绘制到屏幕上。
参考链接
https://www.html5rocks.com/zh/tutorials/internals/howbrowserswork/#Parsing_general
https://developer.mozilla.org/zh-CN/docs/Web/Performance/How_browsers_work
https://zhuanlan.zhihu.com/p/25380611
https://segmentfault.com/a/1190000014520262
